PO.DAAC has traditionally stored checksum files alongside data files in the archive. With the move to the Earthdata cloud, PO.DAAC will now store checksum information in granule metadata accessible through a search interface. While there is a programmatic (API-based) approach to querying for data file checksums, this tutorial will focus on the interactive approach using the Earthdata Search User Interface.
Background
For many years, PO.DAAC has been providing checksum files alongside each data file to allow data users and PO.DAAC operations staff to collectively verify the integrity of the data files in our archive and distribution services. As we’ve been migrating our legacy data as well as publishing new data in NASA’s Earthdata Cloud, our provisioning of checksum information has been updated. Rather than continuing to store checksum information in standalone files, we are storing and distributing checksum information as metadata catalogued in a database known as the Consolidated Metadata Repository (CMR). CMR uses a variety of schemas following a Unified Metadata Model (UMM), of which there is a UMM tailored to data file (or granule) metadata known as UMM-G. Along with each data file we ingest into CMR, which is discoverable in NASA’s Earthdata Search, we likewise generate a unique UMM-G metadata record that is also discoverable and queryable, providing information about the data file as well as information about the distribution endpoints (e.g., S3 direct-access, HTTP-based access, and/or subsetting/transformation services). This UMM-G record also includes the checksum that is generated for each data file.
Another change that has been made is with regard to the type of checksums we are storing. For the majority of our legacy datasets, we are continuing to store the MD5-based checksums. For many of our newer datasets, we are storing checksums using a newer SHA-based checksum, which can be encrypted either as 256-bit or 512-bit. Both of these checksum technologies are based on open-source protocols, with software that is freely available on virtually any platform (i.e., Windows, Mac OS, Linux).
Accessing Earthdata Search
To narrow down your selection to cloud-based datasets, you may start here: https://podaac.jpl.nasa.gov/datasetlist?provider=POCLOUD
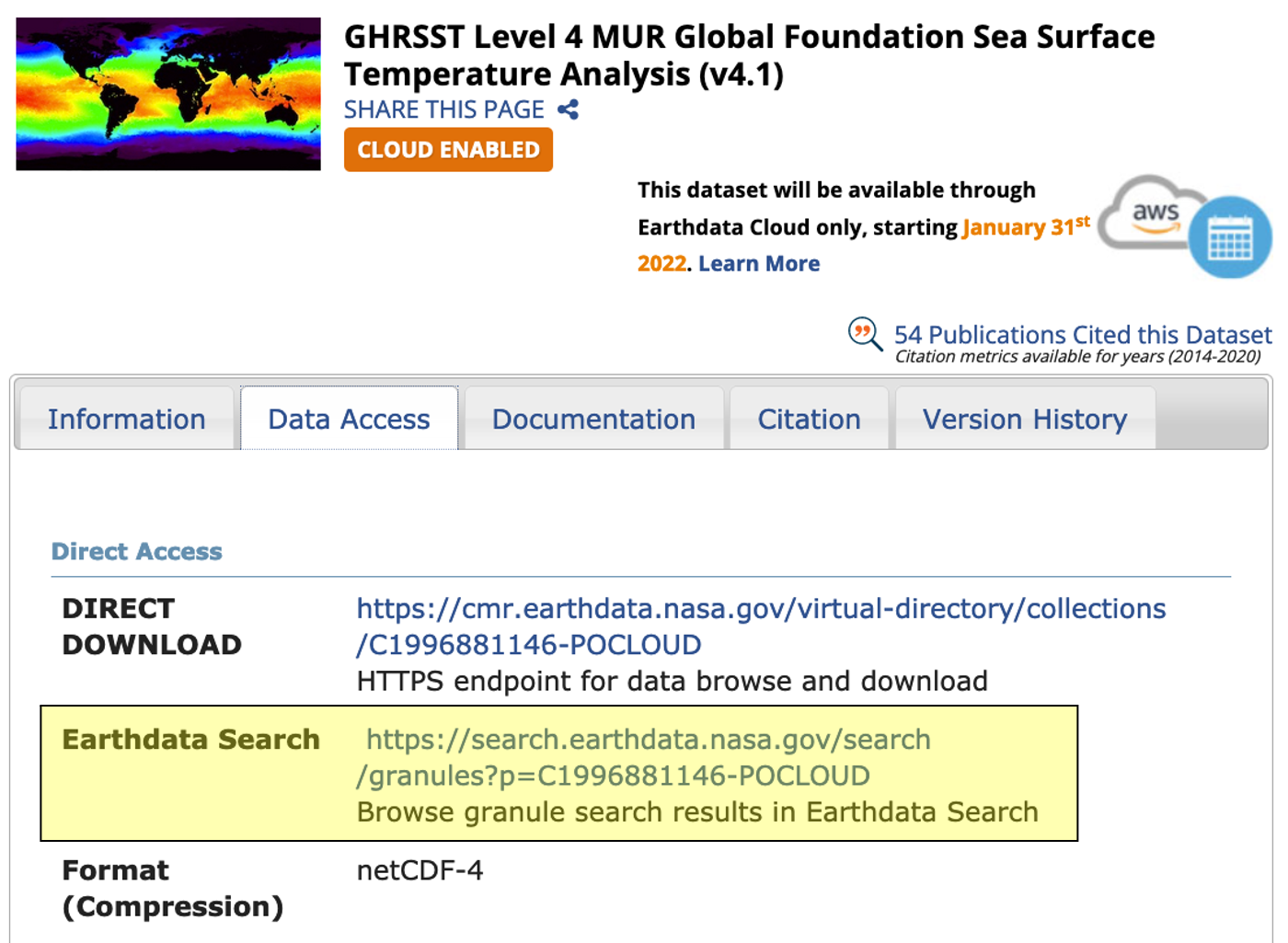
When navigating a specific PO.DAAC dataset landing page (see example below), you’ll want to direct yourself to the ‘Data Access’ tab. The landing page in the example below can be found here: https://podaac.jpl.nasa.gov/dataset/MUR-JPL-L4-GLOB-v4.1
Accessing Checksum Information
Once you locate the ‘Earthdata Search’ URL (see the highlighted box in the example above), you will click on that link, which will take you to the Earthdata Search page for access to all of the granule results. Below is an example of what that Collection page looks like.
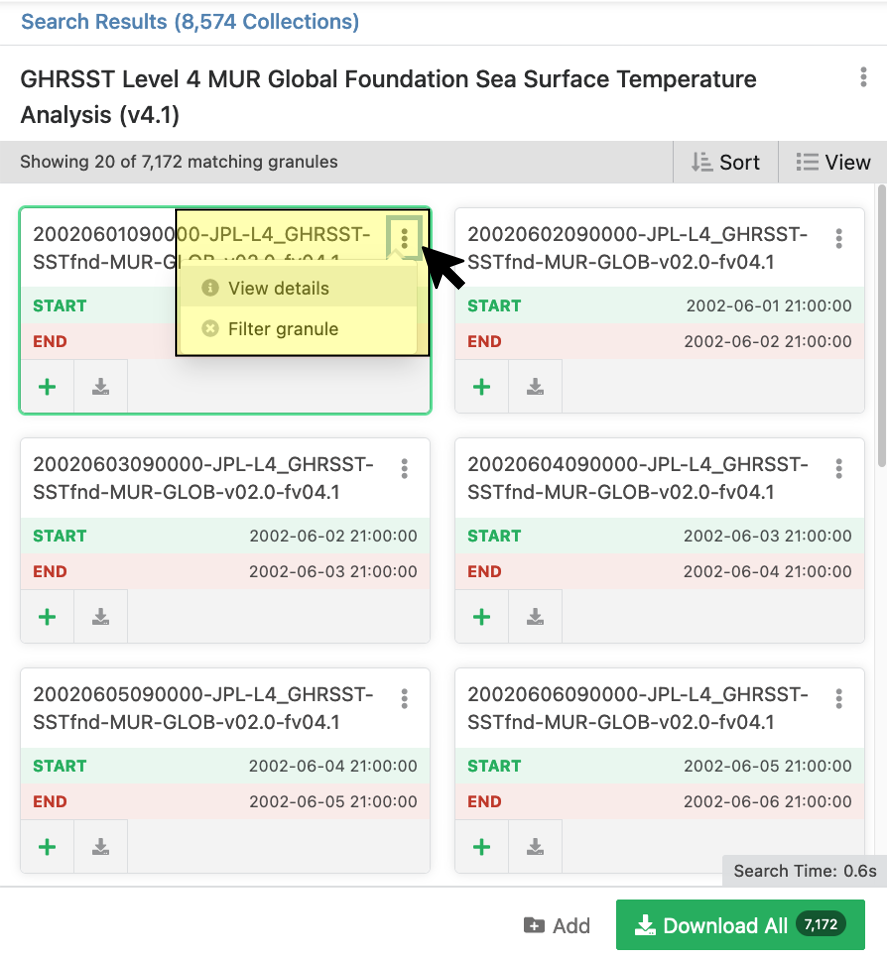
In the above example, you will notice in the highlights box in the top-left an arrow that points to 3 vertical dots. When you click on those dots, a new box will appear that provides additional options. The option to select from here is ‘View details’, which will take you to the UMM-G record that is specific to the data file in that box. The screen grab below provides an example of what that UMM-G page looks like.

In the example above representing a sub-section of the UMM-G metadata, you will notice a block that says “archiveAndDistributionInformation”. It’s within this block that you will then find the checksum information. The highlighted box contains the checksum that is computed on the native netCDF data file that is stored in the cloud-based archive. The checksum above (not highlighted) contains the computed checksum of the original checksum file itself. Another thing to take note of in this example is the “algorithm” field, which in this case states “MD5” as the checksum algorithm that was used.
While this tutorial doesn’t directly cover API-based access, there are a number of previous tutorials and notebooks that can be referenced on that topic. By leveraging CMR, one can use any number of programming languages to search CMR through it’s API. PO.DAAC provides a wide variety of Tutorials (click here for more info) for programmatic access to cloud-based data and metadata (primarily via python-based Jupyter notebooks), but the techniques can apply to many other common programming languages.